The Agentic Coding Landscape
At the start of 2024, everyone was talking about agents. By the end, almost no one could point to one that actually worked reliably. Then February 2025 arrived, and Anthropic quietly released Claude Code. A few months later, OpenAI shipped Codex CLI, Google released Gemini CLI, and AWS launched Kiro. Every major lab had an agentic coding product by mid-year. GitHub’s research found adoption rates of 16–23% across open-source repositories — extraordinary for technology that was only months old.
The landscape that crystallised is worth mapping carefully, because it is not flat. There are distinct layers, and understanding how they relate to each other changes how you choose tools, advise customers, and think about what comes next.
“What is an agent? It’s just an LLM, a loop, and enough tokens. But the importance of the agentic loop hits home when you see it re-enter its own solution and fix it.” — The New Stack, December 2025
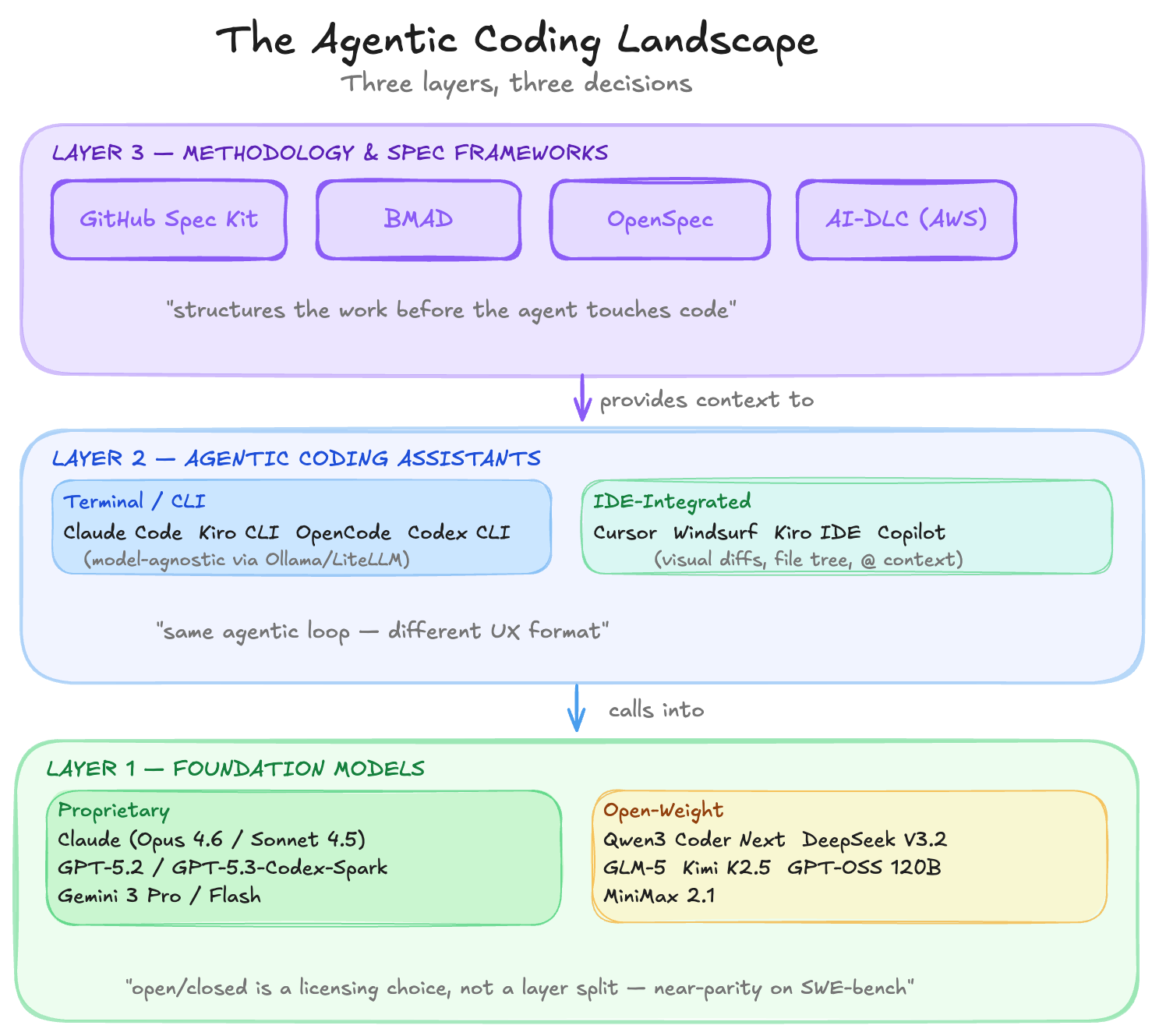
Layer 1 — Foundation Models
Every agentic coding tool is ultimately a wrapper around a foundation model. The model is the intelligence — the rest is scaffolding. The most important structural observation about this layer is that proprietary and open-weight models belong here together. They are not different layers; they are different licensing postures for the same category of thing. The decision you make at this layer is about access, cost, data sovereignty, and performance trade-offs — not about architecture.
The meaningful dimensions to evaluate models on are coding benchmark scores (SWE-bench Verified, LiveCodeBench, Terminal-Bench), context window size, tool-calling fidelity, reasoning depth, and cost per token — not whether they are open or closed.
Proprietary Models
The three dominant families are Anthropic’s Claude, OpenAI’s GPT-5.2, and Google’s Gemini 3. You access these through an API or through the tools that wrap them. You do not own or control the weights.
Within the Claude family, Opus 4.6 (released February 2026) is the current flagship, optimised for complex agentic and coding tasks. Sonnet 4.5 remains the everyday workhorse — fast, capable, the default model in most tools including Cursor, Kiro, and OpenCode. Haiku 4.5 handles high-volume or latency-sensitive work. The Claude family made agentic coding viable: Sonnet 4 was the first model widely described as “smart enough to be useful” in agentic settings, not just impressive in demos.
GPT-5.2 is OpenAI’s current flagship, with a 400K token context window and near-perfect scores on AIME 2025 math benchmarks. The GPT-5.2 Codex variant is purpose-built for long-running agentic coding sessions. OpenAI also just released GPT-5.3-Codex-Spark in research preview — a real-time coding model with 15x faster generation. OpenAI’s consumer mindshare remains enormous even as model quality competition intensifies.
Gemini 3 (Pro and Flash) is Google’s response, and it is a serious one — Google reportedly triggered an internal “Code Red” at OpenAI upon its release. The Pro variant supports 1M+ token context natively, with deep Google Workspace integration. Gemini 3 Flash is the low-latency tier.
Open-Weight Models
2025 was a breakout year for open-weight coding models, driven almost entirely by Chinese labs. DeepSeek R1 (released January 2025 under MIT license) set the tone — a small team demonstrating frontier-level performance and then giving the weights away freely. Into early 2026, that momentum has only accelerated.
DeepSeek V3.2 (DeepSeek AI · MIT) The current production release. Strong on coding (73.1% SWE-bench Verified, 83.3% LiveCodeBench v6), self-hostable, and aggressively priced at ~$0.07/M input tokens with cache hits. DeepSeek V3.2 Exp (an experimental variant) is also available. DeepSeek R1 in early 2025 was the watershed moment that opened the open-weight floodgates.
Qwen3 Coder Next (Alibaba · Apache 2.0) The latest release from Alibaba’s Qwen team, just dropped in early February 2026. Successor to Qwen3 Coder 480B, it achieves over 70% on SWE-bench Verified using only 3B active parameters — a remarkable efficiency leap. 256K context, dual rapid/deep-thinking modes, 358 programming languages supported. Now available on Amazon Bedrock. The most downloaded open model family globally.
Kimi K2.5 (Moonshot AI · Open Weight) Released January 26, 2026. Moonshot AI’s successor to Kimi K2, featuring native multimodality and a novel “Agent Swarm” architecture that can auto-schedule up to 100 sub-agents in parallel, reducing large task completion time by up to 80%. 76.8% on SWE-bench Verified; 85.0% on LiveCodeBench v6. Already available on Amazon Bedrock and NVIDIA NIM. Strong agentic coding performance makes it the most compelling open-weight model for agent-native workflows right now.
GLM-4.7 / GLM-5 (Z.AI · Open Weight) Z.AI has iterated rapidly past GLM-4.5. GLM-4.7 is the current stable release; GLM-5 is the new flagship, described as engineered specifically for “complex systems design and long-horizon agent workflows.” Both are now available on Amazon Bedrock alongside a GLM-4.7 Flash lightweight variant. GLM-5 rivals leading closed-source models on production-grade, large-scale programming tasks.
GPT-OSS 120B (OpenAI · Open Weight) 116.8B total, 5.1B active per token via MoE. OpenAI’s open-weight entry, strong on reasoning. Weaker on multilingual tasks; strongest in well-scoped agentic applications.
The headline from this layer: open-weight models have effectively closed the gap with proprietary models for coding tasks. Kimi K2.5, Qwen3 Coder Next, and DeepSeek V3.2 are all competing directly with Claude Opus 4.5 and GPT-5.2 on SWE-bench and LiveCodeBench, at a fraction of the cost. For enterprises with data sovereignty requirements, this is no longer a compromise — it is a legitimate first choice.
Layer 2 — Agentic Coding Assistants
These tools wrap a foundation model in an agentic loop: read files, plan steps, act on the codebase, observe results, correct errors, repeat. That is the essential pattern — everything else is UX. Which means CLI tools and IDE tools belong in the same layer. Claude Code and Cursor are doing the same fundamental thing; one delivers it through a terminal, the other through a graphical editor.
The most practical way to compare these tools is by experience format: where does the agent live, and how do you interact with it?
| Terminal / CLI | IDE-Integrated | |
|---|---|---|
| Code review | Text diffs in the terminal | Inline diffs with accept/reject controls |
| Context input | Files referenced by path or flag | @ mentions, open tabs, file tree selection |
| Codebase awareness | Agent reads files via shell tools | Agent reads from open project with full index |
| Automation | Scriptable, pipeable, runs in CI | Interactive sessions only |
| Model switching | Config file or flag | Model selector in the UI |
| Examples | Claude Code, Kiro CLI, OpenCode, Codex CLI | Cursor, Windsurf, Kiro IDE, GitHub Copilot |
In practice, most serious practitioners end up using both — a CLI agent for SSH sessions, automation scripts, and server-side work; an IDE agent for active feature development where visual diff review matters. The tools themselves are converging on this: Kiro ships both formats under a single subscription, and OpenCode runs as a TUI, a desktop app, and an IDE extension simultaneously.
Terminal-Native Tools
Claude Code (Anthropic) launched in February 2025 and defined the category. It introduced the CLAUDE.md convention — a project-level markdown file that persists instructions, style preferences, and codebase context across sessions. Its tight integration with Claude’s extended thinking and tool-use made it immediately effective for complex, multi-file tasks. Contrary to a common assumption, Claude Code is not locked to Anthropic models: as of January 2026, Ollama v0.14.0 implemented full Anthropic Messages API compatibility, meaning you can point Claude Code at any local or cloud open-weight model by setting ANTHROPIC_BASE_URL=http://localhost:11434 and running claude --model qwen3-coder (or glm-4.7:cloud, minimax-m2.1:cloud, etc.). LiteLLM provides an equivalent proxy path for teams who want to route Claude Code to any OpenAI-compatible endpoint.
OpenAI Codex CLI followed in May, powered by OpenAI’s Codex model family and usable via a ChatGPT subscription — a meaningful accessibility advantage. Its cloud-based “Codex web” variant can run async tasks for up to 24 hours independently.
Gemini CLI (Google, June) brought Gemini into the terminal as open-source. Strong on Google service integrations; third-party MCP configuration has been rougher in practice.
Kiro CLI (AWS) is the most relevant entrant for platform teams and enterprise contexts. It builds on the Q Developer CLI’s agent infrastructure — including MCP, steering files, and custom agents — and adds social login, a curated model selector, and enterprise IAM Identity Center support. As of February 10, 2026, Kiro added open-weight model support in both the IDE and CLI: DeepSeek V3.2 (0.25x credit multiplier, strong for agentic workflows and multi-step tool calling), MiniMax 2.1 (0.15x, strong for multilingual programming and UI generation across web, Android, and iOS), and Qwen3 Coder Next (0.05x, purpose-built for long agentic coding sessions, especially in the CLI). All three are available to free and paid users with inference running in AWS US East.
OpenCode is the open-source counterpart to all of the above. 100,000+ GitHub stars, 2.5 million monthly active developers, support for 75+ providers — including local models via Ollama, GitHub Copilot subscriptions, and any OpenAI-compatible API. Built by the same team behind terminal.shop, it has a polished TUI and a client/server architecture that allows remote driving from a mobile device. If Claude Code’s constraint is model lock-in, OpenCode’s answer is to have no constraints at all.
IDE-Integrated Tools
Cursor remains the market incumbent. A VS Code fork that pioneered deep LLM integration into the editing experience. Its Composer/Agent Mode plans and executes across multiple files. Excellent for solo developers on well-scoped projects with fast feedback loops. Can struggle on very large codebases and lacks meaningful team-coordination features.
Windsurf (formerly Codeium, now owned by Cognition) introduced the Cascade feature, which automatically retrieves relevant context without manual file tagging. Its proprietary SWE-1.5 model is 13x faster than Sonnet 4.5 for inline completions; Fast Context retrieves codebase context 10x faster than standard approaches. Stronger than Cursor for large codebases, monorepos, and enterprise team workflows.
Kiro IDE (AWS, launched July 2025, GA November 2025) is the most architecturally distinctive entrant. Built as a Code OSS fork, it puts spec-driven development — not vibe coding — at the centre of the workflow. The IDE, CLI, and autonomous cloud agent are unified products, not separate tools. Pricing: $20/$40/$200 per month for Pro/Pro+/Power, with free credits for startups.
GitHub Copilot Agent Mode (VS Code) should not be underestimated. For teams already in the GitHub ecosystem, this is the lowest-friction path to agentic workflows. Copilot now plans tasks, edits files, executes terminal commands, and iterates on feedback — without switching tools or changing authentication.
“Developers in 2023 wanted better autocomplete. In 2024, they wanted multi-file editing. In 2025, they delegate entire workflows to agents while reviewing another PR.” — RedMonk, December 2025
Layer 3 — Spec-Driven Development Frameworks
This layer is genuinely distinct from the other two. It is not about model access or agent runtime. It is about how you structure the work before the agent touches code — and it emerged as the critical missing piece in 2025.
The problem spec-driven development solves is well-understood by anyone who has worked with agentic tools on real projects: LLMs are exceptional at small, clearly scoped tasks and they drift badly on complex, long-horizon ones. Without a durable, versioned specification as the agent’s ground truth, you end up either babysitting every step or accepting significant output quality degradation. The spec is the solution.
The general pattern across all frameworks: capture intent formally, have AI generate clarifying questions and a plan, get human sign-off, then execute against the approved plan. Code becomes the last-mile output of a rigorously defined specification.
GitHub Spec Kit
Microsoft’s open-source implementation, delivered as slash commands for GitHub Copilot. A multi-phase flow: constitution (project rules and constraints) → specify (requirements and user stories) → clarify (AI-generated clarifying questions) → plan (task decomposition) → implement. Best for teams already in the GitHub ecosystem who want a structured but lightweight workflow without adopting a new tool.
BMAD Method
Breakthrough Method for Agile AI-Driven Development. The most ambitious open-source framework: 21 specialised AI agent personas (Analyst, Product Manager, Architect, Developer, QA, Scrum Master, and more), 50+ guided workflows, cross-agent file-based communication via structured markdown artefacts. Works with Claude Code, Cursor, Windsurf, and any agent runtime. Studies report 55% faster completion compared to ad-hoc prompting. Best for large greenfield projects requiring full multi-role coordination. Overkill for routine feature work.
OpenSpec
The minimal, token-efficient alternative. Diff-based and designed specifically for brownfield (existing) codebases where you are making incremental changes rather than building from scratch. Best for ongoing maintenance, refactoring, and iterative feature work on established codebases.
AI-DLC (AWS)
The AI-Driven Development Lifecycle is AWS’s openly published methodology, introduced at AWS DevSphere 2025 and subsequently open-sourced as steering files compatible with Kiro, Claude Code, Amazon Q Developer, Cursor, and GitHub Copilot.
AI-DLC’s key insight is that the workflow itself should be adaptive. Other frameworks prescribe a fixed sequence of phases regardless of task complexity. AI-DLC asks the agent to recommend which phases to run and how deep to go, based on the nature of the intent. A simple utility function does not need full architectural modelling. A new distributed system does.
The three phases — Inception, Construction, Operations — map directly to how teams already think about delivery. “Mob Elaboration” (structured collaborative requirements with AI) replaces the long requirements document. “Bolts” replace sprints — shorter, more intense cycles measured in hours or days rather than weeks. Human approval gates separate each phase; AI proposes, humans always approve before execution advances.
To use it: download the open-source steering files from awslabs/aidlc-workflows, copy the core workflow to your project’s CLAUDE.md or AGENTS.md, and begin any session with "Using AI-DLC, ..." — the workflow activates automatically.
What This Means in Practice
A few observations that matter for how teams should think about adopting this landscape.
The agentic loop changes the developer role, not just developer speed. Spotify declared in December 2025 that their best engineers had not written a single line of code since deploying their internal Claude Code-based system. Engineers focused on review and architecture; the agent handled implementation. This is not an outlier — it is the direction. The role is shifting from code producer to orchestrator and validator.
The methodology layer is the most underappreciated investment. Most tool evaluations focus on Layer 2 (which IDE, which CLI) and Layer 1 (which model). But the organisations getting the most leverage are the ones who have invested in Layer 3. A well-structured spec delivered to a mediocre model consistently outperforms a poorly-scoped prompt delivered to the best model. Adopt AI-DLC, BMAD, or Spec Kit — or build your own equivalent through project-level steering files — before you optimise anything else.
Open-weight models have crossed the enterprise viability threshold. For organisations in regulated industries, or APJ markets with strict data residency requirements, the ability to run Qwen3 Coder Next or GLM-5 on Bedrock or on-premise hardware — at performance levels now genuinely competitive with Claude Opus 4.5 and GPT-5.2, and at a fraction of the cost — is a legitimate first choice, not a compromise. Both models are now available directly on Amazon Bedrock.
Parallel async execution is the next unlock. The most advanced pattern emerging in late 2025 — Kiro’s autonomous agent, Codex web, the “parallel coding lifestyle” — is not about one agent working faster. It is about running ten tasks concurrently across multiple repositories while you work on something else. Getting the methodology layer right is the prerequisite. Persistent memory, multi-repo context, and governance controls come next.
Conclusion
If you are starting from zero: pick a model (Claude Sonnet 4.5 or Opus 4.6 for the path of least resistance; Qwen3 Coder Next or GLM-5 if data sovereignty matters and you want to run on Bedrock or on-premise), pick an agent runtime that matches your team’s workflow (Kiro if you want AWS integration and spec-driven support baked in; Claude Code if you want the most mature CLI agent — and note it supports open-weight models via Ollama or LiteLLM if you want to swap the backend; OpenCode if you want a fully open-source runtime with no platform dependency), and adopt AI-DLC or Spec Kit as your methodology layer for anything more complex than a single-file change.
The tools will keep evolving rapidly. The mental model — three layers, each solving a distinct problem — will stay stable. Orient around the layers, not the specific products, and you will navigate the churn without losing your footing.