Memahami scale cube sebagai salah satu pendekatan scaling pada sebuah aplikasi
 Photo by Kenny Eliason / Unsplash
Photo by Kenny Eliason / Unsplash
Jika kita beruntung, sebuah aplikasi yang kita kembangkan akan bekerja dengan baik, dan dipakai oleh banyak sekali pengguna. Saat ini terjadi, kita akan mempunyai sebuah happy problem — melakukan scale pada aplikasi tersebut untuk mengakomodasi jumlah pengguna yang semakin meningkat.
Pada tulisan kali ini, kita akan membahas tentang scale cube sebagai salah satu pendekatan untuk memutuskan bagaimana kita akan melakukan scaling.
Disarikan dan diterjemahkan dari The Art of Scalability (Abbot, et al.), scale cube adalah sebuah konsep untuk membantu kita memutuskan tentang bagaimana melakukan pemisahan layanan, data dan transaksi, sehingga kita dapat melakukan scale pada aplikasi. Chris Richardson, melalui Microservice Patterns mengilustrasikan scale cube sebagai berikut.
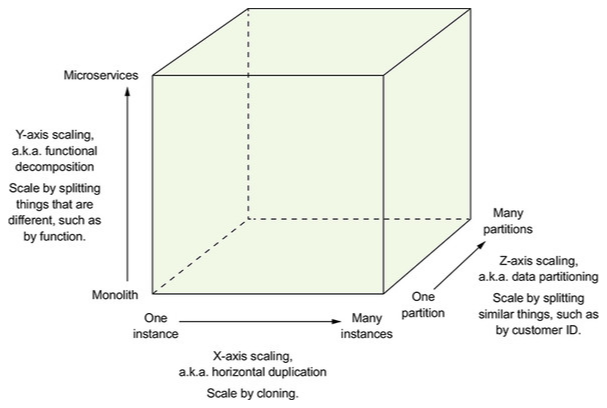
Sebuah kubus di atas terdiri dari 3 sumbu — X, Y dan Z — yang masing-masing mewakili pendekatan scaling yang akan kita lakukan.
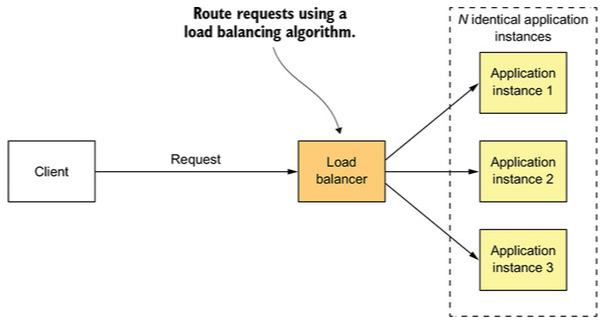
Scaling pada Sumbu X — Melakukan Load Balance pada Request
Pendekatan ini adalah cara yang paling mudah untuk melakukan scaling pada aplikasi. Kita hanya perlu meletakkan server aplikasi di belakang load balancer, dan load balancer yang akan membagi traffic ke semua instances yang ada. Pendekatan ini biasanya dilakukan untuk melakukan scaling pada aplikasi monolith.
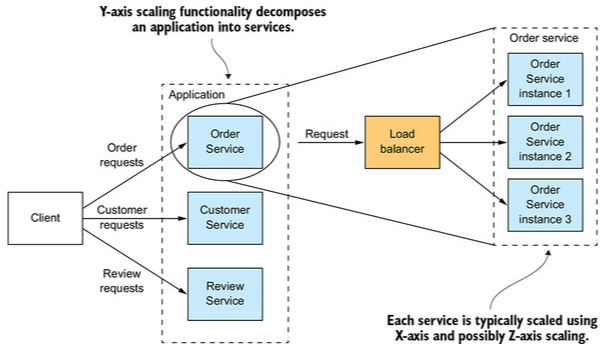
Scaling pada Sumbu Y — Melakukan Dekomposisi Monolith menjadi Microservices
Pada pendekatan ini, setiap fungsionalitas (domain bisnis) pada aplikasi akan berdiri secara independen (terjadi dekomposisi aplikasi menjadi service yang lebih kecil).
Pendekatan ini tidak hanya menyelesaikan masalah capacity dan availability sebuah aplikasi, tetapi juga melakukan scaling sebuah tim (organisasi). Setelah kita melakukan scaling dengan pendekatan sumbu Y, kita masih bisa melakukan scaling lebih lanjut dengan melakukan pendekatan scaling sumbu X dan Z seperti pada ilustrasi berikut.
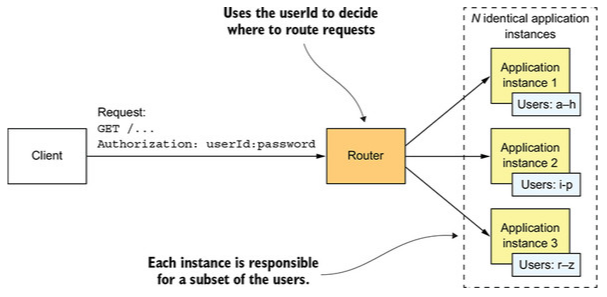
Scaling pada Sumbu Z — Membagi Traffic Berdasarkan Request Attributes
Pendekatan ini dilakukan dengan cara meletakkan router (misalnya, proxy server) untuk mengidentifikasi atribut pada setiap request yang datang. Atribut yang digunakan misalnya segmen pengguna, lokasi pengguna, dsb.
Router akan membagi traffic ke setiap server berdasarkan atribut yang telah ditentukan. Setiap server hanya bertanggung jawab untuk sebagian traffic yang mengandung atribut miliknya.
Pada ilustrasi di bawah, atribut yang diidentifikasi adalah userId. Server 1 hanya bertanggung jawab untuk user A hingga H, server 2 hanya bertanggung jawab untuk user I hingga P, dan server 3 bertanggung jawab untuk user R hingga Z.